
目标重识别的本质问题
目标重识别的本质问题在我看来就是图像检索问题。 分别对一张目标图片与资料库中的数据图片做特征提取。 分别计算特征距离,选取最接近的图片。
传统目标重识别存在问题
- 无法避免的领域差异 : 将训练好的模型应用到新的场景下,无法避免的性能下降。 城市A中训练好的模型, 在城市B中可能就性能下降的厉害。 或者说, 在market 训练集上表现良好的模型在真实应用场景中可能失效。
- 数据标注的人工成本太大。 在多个场景下分别收集数据,部署训练模型不现实也不符合工业应用。
解决方法1 , 领域自适应任务
基本方案: 利用有标签的源域数据, 与无标签的目标域数据,进行训练。 从而在目标域也有很好的效果。 但源域与目标域的图片种类不同。 类似于无监督迁移问题。
两种解决方案:
伪标签类 1: 产生伪标签,聚类, 或者利用图片的相似性。 2: 利用伪标签进行训练, 与一般的有监督任务类似。一般采用分类loss等。 3: 大部分的伪标签类算法会在源域进行预训练。 然后再按照步骤一,二进行。
预转换法: 源域与目标域的风格迁移。 利用Gan对抗网络等,将图片风格进行转换。 最大的保留了原图片的细节信息。
解决方法2,无监督行人重识别任务
解决方案, 伪标签法。 与领域自适应方法基本类似。
过程详解
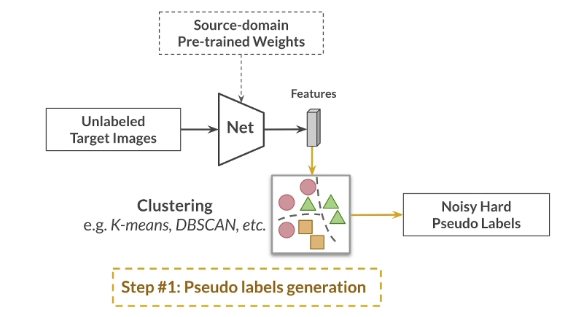
- 传统方法 baseline 基于聚类的伪标签法

- 在源域上利用有标签的数据进行预训练。得到源域网络。
- 利用无标签的目标域数据进行训练
- 利用聚类算法产生伪标签(聚类的具体算法不做演示k——means等算法),该算法是有噪声的。
- 利用伪标签训练目标域模型。
- 如上图, 采用传统的Triplet Loss 与classification loss 等传统的Reid 损失函数进行训练,交替进行。 直到模型收敛为止。
- 传统方法的主要问题
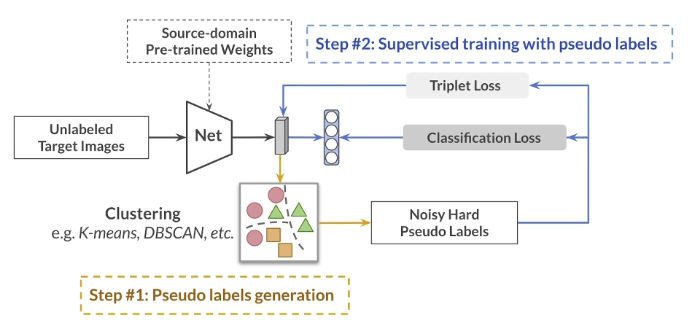
 聚类算法并不完善。有噪声出现。 其次, 我们并不知道在目标域上有多少分类。
聚类算法并不完善。有噪声出现。 其次, 我们并不知道在目标域上有多少分类。
解决方法
- 利用软标签,减少硬标签造成的影响。 但是不可以直接用网络的预测来作为网络的监督学习。 这样会放大误差。
- 同时训练两个网络,相互监督。形成协同训练的模式。 但是还是有误差放大的风险。
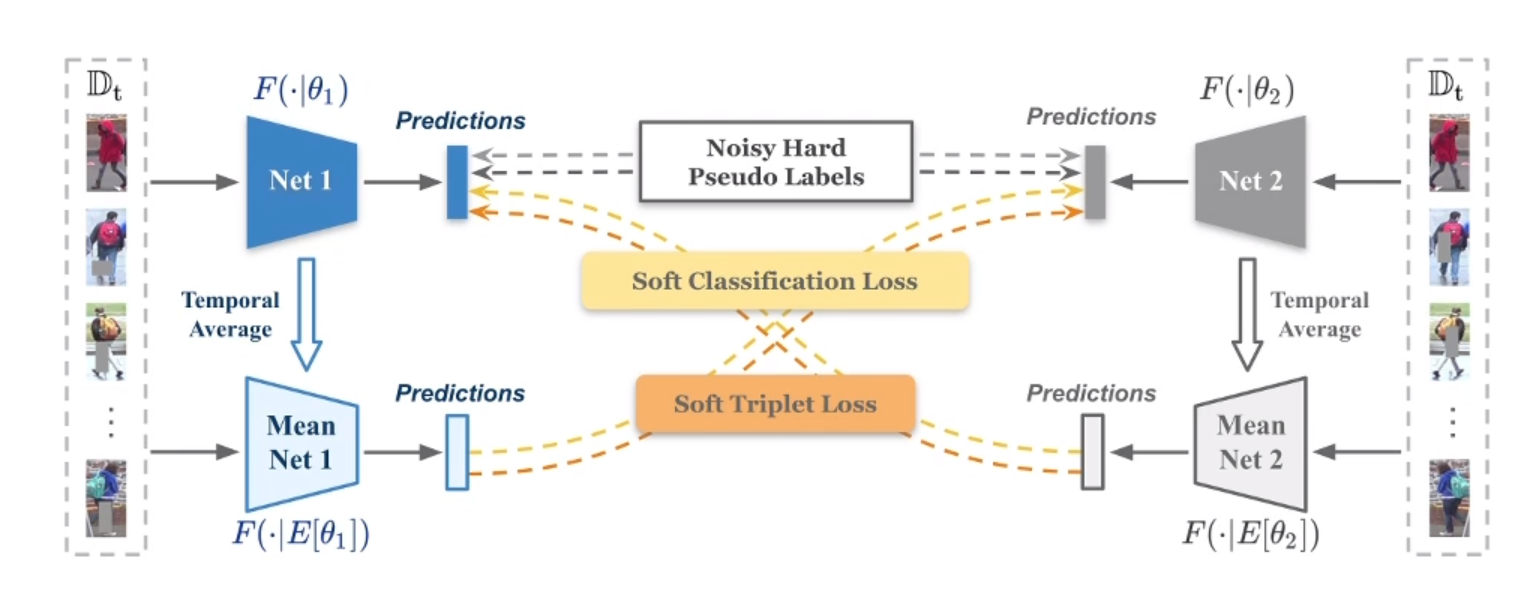
- 提出Mutual Mean_Teaching网络模型。
- Mutual Mean_Teaching过程详解 - Mutual Mean_Teaching 包含两个协同训练网络,每个网络本身还有一个教师网络模型Mean Net - 两组照片,进行随机增强,分别输入两组网络以及网络中的Mean Net 模型。 - 将Mean Net 模型的预测值(软标签)作为对方网络的监督学习标签进行训练。 简单来说,就是Mean Net1 监督Net2 ,Mean Net2 监督 Net1。
- Mean 网络模型不用反向传播进行更新。(这里的更新方式暂时没有看懂)
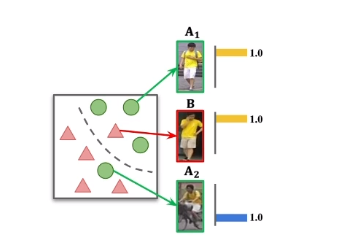
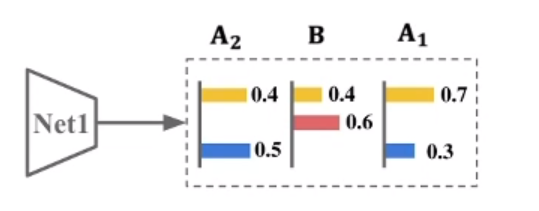
- 为什么要加入Mean Net 网络? 如上图,直接用两个模型相互监督,输出值特别相似,容易让模型崩溃。 《Deep mutual learning. CVPR 2018》。 加入Mean Net网络,其更新不依赖于反向传播,具有更好的输出独立性。形成更好的伪标签。
- 损失函数暂时不写, 具体看论文。
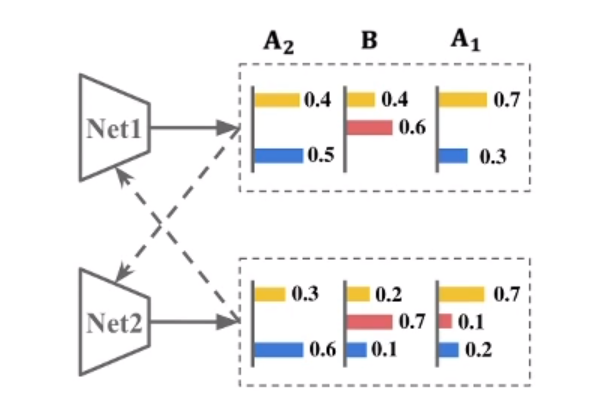
 如上图,直接用两个模型相互监督,输出值特别相似,容易让模型崩溃。 《Deep mutual learning. CVPR 2018》。 加入Mean Net网络,其更新不依赖于反向传播,具有更好的输出独立性。形成更好的伪标签。
如上图,直接用两个模型相互监督,输出值特别相似,容易让模型崩溃。 《Deep mutual learning. CVPR 2018》。 加入Mean Net网络,其更新不依赖于反向传播,具有更好的输出独立性。形成更好的伪标签。